#data cleaning script
import pandas as pd
df = pd.read_csv('fareway_shenandoah_bacon.csv',index_col=False)
df
zip_codes_list = pd.read_csv('iowa_zip_lookup.csv',index_col=False)
zip_codes_list
zip_codes_list = zip_codes_list.drop('County',axis=1)
df = df.drop(df.columns[0], axis=1)
df=df.reset_index(drop=True)
df = df.drop(df.columns[5], axis=1)
df = df.drop(df.columns[4], axis=1)
df=df.rename(columns={"au-target": "Product Name", "au-target 2": "Original Price", "product-price": "Selling Price", "pc-amount": "Weight in lb"})
df['Weight in lb']=df['Weight in lb'].fillna('1 lb')
df
df['Weight in lb']=df['Weight in lb'].replace('16 oz', '1 lb', regex=True)
df['Weight in lb']=df['Weight in lb'].replace(' Box', '', regex=True)
#df['Weight in lb']=df['Weight in lb'].replace(' lb', '', regex=True)
df['Weight in lb']=df['Weight in lb'].replace('Approx ', '', regex=True)
df['Weight in lb']=df['Weight in lb'].replace(' LB Each', '', regex=True)
df['Selling Price']=df['Selling Price'].replace('/LB', '', regex=True)
def convert_to_pounds(weight):
if isinstance(weight, str):
if 'oz' in weight:
ounces = float(weight.strip(' oz'))
pounds = ounces / 16
return f"{pounds} lb"
elif 'lb' in weight:
return weight
return weight
df['Weight in lb'] = df['Weight in lb'].apply(convert_to_pounds)
df['Zip Code'] = '51601'
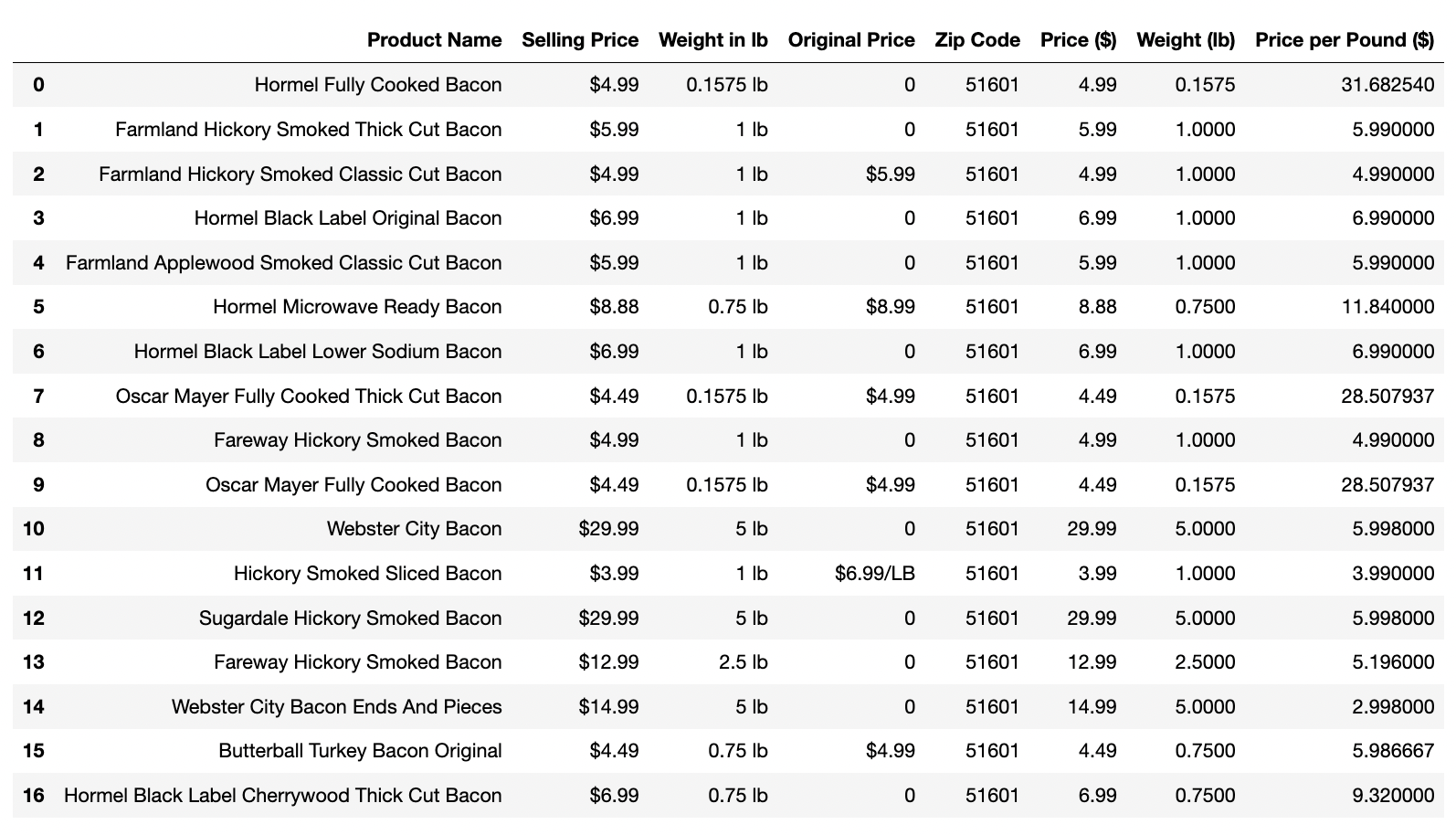
df
def convert_to_price_per_pound(row):
price_value = float(row['Selling Price'].strip('$'))
weight_str = row['Weight in lb'].split(' ')[0]
weight_value = float(weight_str)
price_per_pound = price_value / weight_value
return pd.Series([price_value, weight_value, price_per_pound], index=['Weight in lb', 'Weight (lb)', 'Price per Pound ($)'])
df[['Price ($)', 'Weight (lb)', 'Price per Pound ($)']] = df.apply(convert_to_price_per_pound, axis=1)
df
from datetime import datetime
# Create a sample DataFrame
# Generate the current date and time
current_datetime = datetime.now().strftime('%Y%m%d_%H%M%S')
# Define the file name with the current date and time
file_name = f'fareway_shenandoah_cleaned_{current_datetime}.csv'
# Output the DataFrame to the CSV file
df.to_csv(file_name, index=False)Week Four Highlights
Monday- Collecting data for the project and working on finding data sources for Heirloom Tomatoes.
Tuesday- Collected in person data at Slater to analyze the housing conditions and amenities there in the first half of the day. Second half was remote where I worked on compiling and cleaning the data.
Wednesday- Created a script which cleaned scraped prices from Fareway Market website for locations Ames, Fort Dodge, Davenport, Iowa City, New Hampton, Clear Lake, Sioux City, Shenandoah in Iowa.
Thursday- Worked to get more data output, discussed presentation and blog wrap ups with team.